
티스토리 뷰
4.1 카프카 컨슈머
4.1.1 컨슈머와 컨슈머 그룹
컨슈머의 특징 중 하나는 병렬 처리가 가능하다. 컨슈머는 컨슈머 그룹(Consumer Group)을 구성해 여러 개의 컨슈머들이 동일한 토픽을 구독할 경우, 각각의 컨슈머는 해당 토픽에서 서로 다른 파티션의 메시지를 받는다.
지연 시간이 긴 작업을 수행할 때, 컨슈머를 추가하여 단위 컨슈머가 처리하는 파티션과 메시지의 수를 분산시키는 것이 일반적인 규모 확장 방식이다.

- 동작 방식: 토픽은 하나 이상의 파티션(Partition)으로 구성된다. 하나의 파티션은 특정 시점에 오직 하나의 컨슈머 그룹 내 단 한 명의 컨슈머에게만 할당될 수 있다. 컨슈머들은 각자 파티션을 하나씩 나눠 맡아 동시에 처리하므로 처리량이 극대화된다.
- 성능과 한계: 처리량을 높이고 싶다면 컨슈머를 추가하면 된다. 하지만 파티션 개수보다 컨슈머가 많아지면, 남는 컨슈머는 할 일 없이 대기하게 되니 리소스 낭비가 발생할 수 있다. (그림의 Consumer 5의 경우 유휴 컨슈머가 됨)
만약 서로 다른 두 개의 애플리케이션(예: 실시간 분석 앱, 데이터 백업 앱)이 토픽 T1의 모든 데이터를 각각 필요로 한다면, 별개의 컨슈머 그룹을 만들면 된다.

예를 들어, 컨슈머 그룹 1이 토픽 T1의 데이터를 처리하고 있는 상황에서, 완전히 새로운 목적을 가진 컨슈머 그룹 2를 추가하면, 그룹 2의 컨슈머들도 토픽 T1의 모든 메시지를 처음부터 독립적으로 가져갈 수 있습니다. 이 두 그룹은 서로에게 전혀 영향을 주지 않는다.
결론적으로,
- 같은 작업을 더 빠르게 처리하고 싶다면, 동일한 컨슈머 그룹에 컨슈머를 더 추가
- 같은 데이터를 다른 목적으로 사용하고 싶다면, 새로운 컨슈머 그룹을 만들기
4.1.2 컨슈머 그룹과 파티션 리밸런스
컨슈머 그룹에 새로운 컨슈머가 추가되거나, 기존 컨슈머가 사라지면(장애 발생, 정상 종료 등) 그룹 내에서 파티션을 재분배하는 과정이 일어난다. 이를 리밸런스(Rebalance)라고 한다.
- 협력적 리밸런스 (Cooperative Rebalance): 과거에는 리밸런싱이 발생하면 모든 컨슈머가 다 멈추는 상태(조급한 리밸런스)가 되어 서비스 전체가 잠시 중단되는 'Stop-the-World' 현상이 있었다. 하지만 버전의 카프카는 협력적 리밸런스가 기본값이다. 이는 전체를 멈추는 대신, 영향을 받는 파티션만 다른 컨슈머에게 넘겨주는 방식으로, 서비스 중단을 최소화한다.
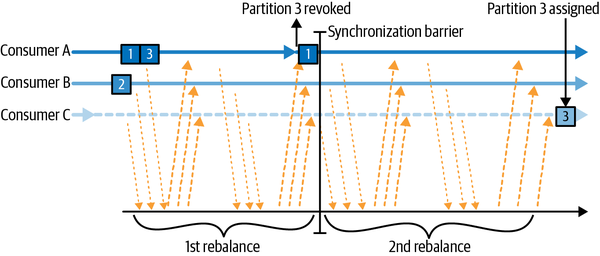
- 그룹 코디네이터와 하트비트: 각 컨슈머 그룹에는 그룹 코디네이터(Group Coordinator)라는 리더 역할을 하는 브로커가 지정된다. 컨슈머들은 이 코디네이터에게 주기적으로 살아있다는 신호, 즉 하트비트(Heartbeat)를 보낸다. 이 신호가 끊기면 코디네이터는 해당 컨슈머에게 문제가 생겼다고 판단하고 리밸런싱을 시작한다.
- 컨슈머가 그룹에 참여하고 싶을 때는 그룹 코디네이터에게 JoinGroup요청을 보낸다. 카프카는 파티션 할당 정책이 기본적으로 내장되어 있어, 컨슈머 그룹 리더는 할당 내역을 Grou[pCoordinator에네 전달한다.
[실제 서비스 상황이라면? ]
실시간으로 사용자 로그를 분석하여 대시보드에 보여주는 서비스를 운영 중이라고 가정해 봅시다. 분석 속도를 높이기 위해 컨슈머를 추가하는 순간, 약 몇 초간 대시보드 업데이트가 멈추는 현상을 경험할 수 있습니다. 이것이 바로 리밸런스 때문입니다. 사용자가 거의 없는 새벽 시간에 컨슈머 수를 조절하거나, 리밸런스 시간을 최소화하는 전략이 필요합니다.
4.1.3 정적 그룹 멤버십
기본적으로 컨슈머가 갖는 컨슈머 그룹의 멤버 자격은 일시적이다. 하지만,배포나 설정 변경으로 컨슈머가 잠시 재시작될 때마다 리밸런싱이 일어나는 것은 비효율적이다. 정적 그룹 멤버십(Static Group Membership)은 이 문제를 해결한다. 각 컨슈머에게 고유 ID(group.instance.id)를 부여하여, 잠시 그룹을 떠났다가 돌아와도 코디네이터가 이전에 담당하던 파티션을 그대로 다시 할당할 수 있다. 덕분에 불필요한 리밸런싱 오버헤드를 크게 줄일 수 있다.
** 하지만, 고유ID를 같은 두 개의 컨슈머가 같은 그룹에 조인할 경우 에러가 발생함
4.2 카프카 컨슈머 생성하기
카프카 컨슈머 인스턴스를 생성하는 것은 KafkaProducer를 만드는 것과 매우 유사하다. 먼저, 컨슈머에 전달할 속성을 담은 자바 Properties 인스턴스를 생성해야한다.
필수 속성 3가지는 다음과 같다.
bootstrap.servers: 카프카 클러스터에 연결하기 위한 커넥션.KafkaProducer와 동일하게 사용된다.key.deserializer: 프로듀서의 직렬 변환기와는 반대로, 바이트 배열을 자바 객체로 변환하는 클래스를 지정해야 한다value.deserializer: 키와 마찬가지로, 값에 대한 역직렬 변환기 클래스를 지정한다
필수는 아니지만 매우 일반적으로 사용되는 네 번째 속성은 group.id이 속성은 KafkaConsumer 인스턴스가 속한 컨슈머 그룹을 지정한다.
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);4.3 토픽 구독하기
컨슈머를 생성한 후, 다음 단계는 하나 이상의 토픽을 구독한다. subscribe() 메소드는 토픽 목록을 매개변수로 받는다.
consumer.subscribe(Collections.singletonList("customerCountries"));정규 표현식을 사용하여 여러 토픽을 구독하는 것도 가능하다. 표현식은 여러 토픽 이름과 일치할 수 있으며, 만약 일치하는 이름의 새 토픽이 생성되면 거의 즉시 리밸런스가 발생하여 컨슈머가 새 토픽에서 데이터를 소비하기 시작한다. 실제 서비스에서 흔하게 사용된다.
consumer.subscribe(Pattern.compile("test.*"));4.4 폴링 루프
컨슈머는 폴링(Polling)을 통해 데이터를 가져온다. consumer.poll() 메소드는 단순한 데이터 조회가 아니라, 컨슈머가 계속해서 살아있도록 하는 패턴이다.
1. 그룹 코디네이터와 통신하여 파티션이 제대로 할당되었는지 확인
2. 리밸런싱이 필요하면 참여
3. 코디네이터에게 하트비트를 보내 생존 신고
4. 실제로 데이터를 가져옴
Duration timeout = Duration.ofMillis(100); // poll() 메서드가 데이터를 기다리는 최대 시간 (밀리초) 설정
while (true) { // 무한 루프: 컨슈머는 일반적으로 지속적으로 Kafka에서 데이터를 폴링
// 1. 데이터 폴링: Kafka로부터 레코드를 가져옴.
// - poll()을 처음 호출하면 GroupCoordinator를 찾고, 컨슈머 그룹에 참여하며, 파티션 할당을 받음.
// - rebalance가 발생하면 poll() 내부에서 처리됨.
// - max.poll.interval.ms보다 오래 poll()을 호출하지 않으면 컨슈머는 죽은 것으로 간주되어 그룹에서 제외됨.
// - 타임아웃 값이 0으로 설정되어 있거나, 이미 컨슈머 버퍼에 처리할 레코드가 있다면, poll()은 즉시 반환
ConsumerRecords<String, String> records = consumer.poll(timeout);
// 2. 레코드 처리: 가져온 각 레코드를 개별적으로 처리
for (ConsumerRecord<String, String> record : records) {
// 레코드 정보가 저장된 List 객체를 리턴함 (topic, partition, offset, key, value)
System.out.printf("topic = %s, partition = %d, offset = %d, " +
"customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
// 각 국가별 고객 수 집계 (예시: 해시 테이블 업데이트)
int updatedCount = 1;
if (custCountryMap.containsKey(record.value())) {
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount);
// 집계 결과를 JSON 형태로 출력
JSONObject json = new JSONObject(custCountryMap);
System.out.println(json.toString());
}
}
// 이 코드는 무한 루프이며, 실제 애플리케이션에서는 루프를 종료하고 컨슈머를 닫는 로직이 추가되어야 함.
// (예시: shutdown 훅 또는 특정 조건에 따른 break 문)4.4.1 스레드 안정성
컨슈머는 스레드에 안전하지 않다. 하나의 컨슈머 인스턴스를 여러 스레드에서 동시에 조작하면 안 된다. 한 애플리케이션에서 여러 컨슈머를 병렬로 실행하고 싶다면, 반드시 컨슈머마다 별도의 스레드를 생성해서 분리해야 한다.
다른 방법으로는 이벤트를 받아서 단일 컨슈머가 이벤트 큐를 채우고, 여러 워커 스레드가 이 큐에서 작업을 수행하도록 한다. 이는 컨슈머가 메시지 수신 및 파싱에만 집중하고, 실제 비즈니스 로직 처리는 워커 스레드에게 위임하여 처리량과 병렬성을 높이는 데 효과적이다.
poll() 메서드의 변경 사항 및 주의사항
과거 Kafka 버전에서 poll() 메서드는 poll(long) 시그니처를 사용했지만, 현재는 더 이상 사용되지 않으며(deprecated), 새로운 API인 poll(Duration)으로 변경되었다. 단순히 인자 타입만 바뀐 것이 아니라, 메서드가 블로킹되는 방식에도 미묘한 의미론적 변화가 있다.
- 이전 poll(long) 메서드: 타임아웃 시간보다 더 오래 걸리더라도 Kafka로부터 필요한 메타데이터를 가져올 때까지 블로킹될 수 있었다.
- 새로운 poll(Duration) 메서드: 타임아웃 제한을 엄격하게 준수하며, 메타데이터를 기다리지 않는다.
참고: 아래 내용은 제가 잘 모르는 용어나 이해를 돕기 위해 AI를 사용한 QnA입니다.
Q. 스레드(Thread)란 무엇인가요?
컴퓨터 과학에서 스레드(Thread)는 프로그램 실행의 가장 작은 단위입니다. 쉽게 말해, 프로그램 내에서 독립적으로 실행될 수 있는 작업의 흐름이라고 생각하시면 됩니다.
프로그램 (Program): 하나의 공장 건물이라고 생각해보세요.
프로세스 (Process): 공장 건물 안에서 특정 제품을 생산하는 독립된 라인 하나 (예: 자동차 생산 라인). 각 라인은 고유의 자원(메모리 공간 등)을 가집니다. 하나의 프로그램이 실행되면 최소 하나의 프로세스가 생성됩니다.
스레드 (Thread): 하나의 생산 라인(프로세스) 안에서 특정 작업을 수행하는 작업자들입니다. 이 작업자들은 같은 라인의 자원(생산 설비, 재료 등)을 공유하면서 각자 다른 세부 작업을 동시에 수행할 수 있습니다.
스레드의 주요 특징:
경량 프로세스 (Lightweight Process): 프로세스보다 생성 및 전환 비용이 적습니다.
자원 공유: 같은 프로세스 내의 스레드들은 해당 프로세스의 메모리 공간, 파일 핸들 등 대부분의 자원을 공유합니다. 이것이 바로 스레드 간 통신이 프로세스 간 통신보다 훨씬 빠르고 효율적인 이유입니다.
동시성 (Concurrency): 스레드를 사용하면 하나의 프로그램 내에서 여러 작업을 동시에 진행하는 것처럼 보이게 할 수 있습니다 (실제로는 CPU 코어 수에 따라 병렬 또는 시분할 방식으로 실행됨).
Kafka 컨슈머와 스레드의 관계:
Kafka 컨슈머는 poll() 메서드를 통해 Kafka 브로커와 통신하고 데이터를 가져옵니다. 이 작업은 네트워크 I/O와 데이터 처리를 포함하므로, 하나의 컨슈머가 다른 무거운 작업을 수행하는 동일한 스레드에 묶여 있으면 poll() 호출이 지연되어 컨슈머가 "죽은" 것으로 간주될 위험이 있습니다.
따라서 Kafka 컨슈머는 스레드 안전성을 보장하지 않으므로, 하나의 컨슈머는 반드시 하나의 스레드에서만 사용해야 합니다. 만약 여러 개의 파티션에서 데이터를 병렬로 처리하고 싶다면, 각 파티션 또는 파티션 그룹당 별도의 스레드를 만들고, 그 스레드 내에서 독립적인 컨슈머 인스턴스를 실행해야 합니다.
Q. '이벤트 큐를 채우고 여러 워커 스레드가 작업 수행' 방식이란?
이 방식은 생산자-소비자(Producer-Consumer) 패턴의 한 형태로, 시스템의 처리량을 늘리고 컨슈머의 안정성을 확보하는 데 널리 사용됩니다.
Kafka 컨슈머의 경우, 다음과 같이 적용할 수 있습니다.
단일 컨슈머 스레드 (생산자 역할):
역할: 이 스레드는 오직 Kafka로부터 메시지를 poll()하고 가져오는 역할만 수행합니다.
작업: poll()을 통해 받은 ConsumerRecord 객체들을 즉시 내부의 공유 큐(Queue)에 넣습니다. 이 큐는 보통 BlockingQueue와 같이 스레드 안전하게 설계된 자료구조를 사용합니다.
장점: poll() 호출이 거의 지연 없이 이루어지므로, 컨슈머가 max.poll.interval.ms 제한 때문에 "죽는" 상황을 방지하고 리밸런싱 문제로부터 비교적 자유로워집니다.
여러 워커 스레드 (소비자 역할):
역할: 이 스레드들은 공유 큐에서 이벤트를 꺼내어 실제 비즈니스 로직(데이터 저장, 가공, 다른 시스템 호출 등)을 처리합니다.
작업: 큐에서 하나의 이벤트를 가져와서 모든 복잡하거나 시간이 오래 걸리는 작업을 수행합니다.
병렬 처리: 여러 워커 스레드가 동시에 작업을 처리하므로 전체 처리량(throughput)을 크게 늘릴 수 있습니다.
부하 분산: 특정 레코드의 처리가 오래 걸리더라도 다른 워커 스레드가 다른 레코드를 계속 처리할 수 있어 시스템의 반응성이 좋습니다.
컨슈머 분리: Kafka 컨슈머의 poll() 루프가 복잡한 비즈니스 로직으로부터 분리되어 훨씬 안정적으로 동작합니다.
왜 이 방식이 유용한가요?
Kafka 컨슈머의 poll() 메서드 내에서는 시간이 오래 걸리는 작업을 피해야 합니다. 예를 들어, 데이터베이스에 쓰거나 외부 API를 호출하는 작업은 네트워크 지연 등으로 인해 poll()이 너무 오랫동안 반환되지 않도록 만들 수 있습니다.
이벤트 큐 방식을 사용하면, poll()은 단순히 데이터를 가져와 큐에 넣는 가벼운 작업만 수행합니다. 실제 무거운 작업은 별도의 워커 스레드에게 위임하므로, poll()은 항상 신속하게 반환되어 컨슈머의 활성 상태를 유지할 수 있습니다. 동시에 여러 워커 스레드가 병렬로 작업을 처리하여 애플리케이션의 전반적인 성능을 향상시킬 수 있습니다.
4.5 컨슈머 설정하기
| 속성명 | 기본값 | 설명 | 중요성 및 용도 |
|---|---|---|---|
bootstrap.servers |
(필수) | Kafka 클러스터에 연결할 초기 브로커 목록입니다. | 필수: 컨슈머가 Kafka에 연결하기 위해 반드시 설정해야 합니다. |
group.id |
(필수) | 컨슈머가 속할 컨슈머 그룹의 ID입니다. | 필수: 메시지 분배와 오프셋 관리를 위해 그룹 ID가 필요합니다. |
key.deserializer |
(필수) | 레코드 키를 역직렬화할 클래스입니다. | 필수: 키 데이터를 올바른 타입으로 변환합니다. |
value.deserializer |
(필수) | 레코드 값을 역직렬화할 클래스입니다. | 필수: 값 데이터를 올바른 타입으로 변환합니다. |
| 데이터 페칭 관련 | |||
fetch.min.bytes |
1 byte | 브로커가 컨슈머에게 데이터를 보내기 전에 모을 최소 바이트 양입니다. | 적은 활동 토픽에서 브로커/컨슈머 부하 감소에 유용하지만, 대기 시간(latency)을 증가시킬 수 있습니다. |
fetch.max.wait.ms |
500 ms | fetch.min.bytes 조건을 충족시키기 위해 브로커가 기다릴 최대 시간입니다. |
잠재적 대기 시간을 제한할 때 사용합니다. fetch.min.bytes와 함께 설정하여 트레이드오프를 조절합니다. |
fetch.max.bytes |
50 MB | poll() 호출 시 컨슈머가 브로커로부터 받을 최대 데이터 크기입니다. |
컨슈머의 메모리 사용량을 제한합니다. 브로커에도 유사한 설정(replica.fetch.max.bytes)이 있습니다. |
max.poll.records |
500 records | poll() 호출 한 번에 반환될 최대 레코드 수입니다. |
한 번의 poll 루프에서 처리할 데이터 양(개수)을 제어합니다. |
max.partition.fetch.bytes |
1 MB | 서버가 파티션당 반환할 최대 바이트 수입니다. | fetch.max.bytes 대신 사용 시 메모리 제어가 복잡해질 수 있어 특별한 이유가 없다면 권장하지 않습니다. |
| 그룹 관리 및 리밸런싱 관련 | |||
session.timeout.ms |
10 seconds | 컨슈머가 하트비트를 보내지 않아도 "살아있는" 것으로 간주되는 최대 시간입니다. | 이 시간 안에 하트비트를 보내지 않으면 죽은 것으로 간주되어 리밸런싱이 트리거됩니다. 낮게 설정하면 실패 감지는 빠르나 불필요한 리밸런싱 가능성이 있습니다. |
heartbeat.interval.ms |
3 seconds (approx.) | 컨슈머가 그룹 코디네이터에게 하트비트를 보내는 빈도입니다. | session.timeout.ms보다 낮게 설정해야 하며, 일반적으로 session.timeout.ms의 1/3 정도로 설정합니다. |
max.poll.interval.ms |
5 minutes | 컨슈머가 poll()을 호출하지 않고 버틸 수 있는 최대 시간입니다. 이 시간을 넘으면 죽은 것으로 간주되어 리밸런싱됩니다. |
하트비트만으로는 감지하기 어려운 메인 스레드 데드락 상황에 대한 안전 장치(fail-safe) 역할을 합니다. |
partition.assignment.strategy |
RangeAssignor |
컨슈머 그룹 내에서 파티션을 할당하는 전략입니다. | [Range]: 각 토픽에서 연속적인 파티션 할당. [RoundRobin]: 모든 토픽의 파티션을 순차적으로 할당. [Sticky]: 균형 잡힌 할당과 리밸런싱 시 파티션 이동 최소화.[Cooperative Sticky]: Sticky와 동일하나, 협력적 리밸런스(일부 파티션 계속 소비) 지원. |
group.instance.id |
(없음) | 컨슈머에 정적 그룹 멤버십을 부여하는 고유 문자열입니다. | 컨슈머의 인스턴스를 고정하여 리밸런싱을 빠르게 할 수 있습니다 (Stateful 컨슈머에 유용). |
| 오프셋 커밋 관련 | |||
auto.offset.reset |
latest |
유효한 오프셋이 없을 때 컨슈머의 시작 위치를 제어합니다. | latest: 최신 레코드부터 시작. earliest: 가장 오래된 레코드부터 시작. none: 유효한 오프셋 없으면 예외 발생. |
enable.auto.commit |
true |
오프셋을 자동으로 커밋할지 여부입니다. | false로 설정하면 수동 커밋을 통해 중복 및 데이터 손실을 최소화할 수 있습니다. |
auto.commit.interval.ms |
5 seconds | enable.auto.commit이 true일 때 오프셋을 자동으로 커밋하는 빈도입니다. |
자동 커밋 시 커밋 주기를 조절합니다. |
offsets.retention.minutes |
7 days | (브로커 설정) 컨슈머 그룹이 비활성화된 후 커밋된 오프셋을 유지하는 시간입니다. | 컨슈머 그룹이 오랫동안 활동이 없으면 오프셋이 삭제될 수 있으므로 주의해야 합니다. |
| 네트워크 및 기타 | |||
default.api.timeout.ms |
1 minute | 명시적 타임아웃이 없는 대부분의 API 호출에 적용되는 기본 타임아웃입니다. | poll() 메서드에는 적용되지 않습니다. |
request.timeout.ms |
30 seconds | 브로커로부터 응답을 기다릴 최대 시간입니다. 이 시간 내에 응답 없으면 연결을 끊고 재접속 시도합니다. | 브로커 부하를 고려하여 너무 낮게 설정하지 않는 것이 좋습니다. |
client.id |
(없음) | 브로커가 클라이언트 요청을 식별하는 데 사용하는 임의의 문자열입니다. | 로깅, 메트릭, 할당량 설정 등에 사용됩니다. |
client.rack |
(없음) | 컨슈머가 위치한 데이터센터 랙(rack) 또는 가용성 영역(zone)을 식별합니다. | 랙 인식 복제본 선택을 통해 성능 및 비용 이점을 얻을 수 있습니다. |
receive.buffer.bytes |
-1 (OS 기본) | TCP 수신 버퍼 크기입니다. | 장거리 네트워크 링크(고지연, 저대역폭)에서 성능 향상을 위해 증가시킬 수 있습니다. |
send.buffer.bytes |
-1 (OS 기본) | TCP 송신 버퍼 크기입니다. | receive.buffer.bytes와 동일한 목적으로 사용됩니다. |
시나리오 예시
글로벌 뉴스 기사를 실시간으로 수집, 분석하는 서비스를 가정
상황 1: 데이터가 적을 때 CPU 낭비가 심하고, 불필요한 네트워크 트래픽이 걱정돼요.
"저희 서비스는 새벽 시간대에는 뉴스 기사 유입이 적어서 컨슈머가 굳이 계속 브로커에 '새 기사 있나요?' 하고 물어볼 필요가 없어요. 너무 자주 물어보니 CPU도 낭비되고 네트워크 트래픽도 아깝네요."
운영자의 설정: fetch.min.bytes와 fetch.max.wait.ms 조정
- fetch.min.bytes (기본값: 1 byte): "최소한 10KB의 새 기사가 모일 때까지는 브로커가 응답을 보내지 마세요!"
- fetch.min.bytes = 10240 (10KB)
- fetch.max.wait.ms (기본값: 500 ms): "하지만 너무 오래 기다리게 하면 안 되니, 아무리 새 기사가 없더라도 최대 500ms(0.5초) 이상은 기다리지 말고 응답을 주세요."
- fetch.max.wait.ms = 500
상황 2: 컨슈머가 갑자기 멈추거나 죽으면, 뉴스 분석에 공백이 생겨요!
"저희 뉴스 분석 컨슈머가 간혹 뻗는 경우가 있는데, 그때마다 데이터 처리가 중단되어서 큰일이에요. Kafka가 빨리 알아채고 다른 컨슈머에게 작업을 넘겨줬으면 좋겠어요."
운영자의 설정: session.timeout.ms, heartbeat.interval.ms, max.poll.interval.ms 조정
- session.timeout.ms (기본값: 10초): "컨슈머가 6초 동안 응답이 없으면 바로 죽은 걸로 간주하고 다른 컨슈머에게 파티션을 넘겨주세요!"
- session.timeout.ms = 6000 (6초)
- heartbeat.interval.ms (기본값: 3초 내외): "컨슈머는 2초마다 '저 살아있어요!' 하고 브로커에게 보고하세요."
- heartbeat.interval.ms = 2000 (2초)
- max.poll.interval.ms (기본값: 5분): "설사 하트비트는 보내더라도, 컨슈머가 30초 이상 poll()을 안 하고 멈춰있으면, 그것도 죽은 걸로 간주해주세요!"
- max.poll.interval.ms = 30000 (30초)
상황 3: 새로운 컨슈머 배포 시, 과거 데이터를 다시 처리하고 싶지 않아요.
"새로운 분석 컨슈머를 배포했는데, 과거 뉴스 데이터까지 전부 다 다시 처리하는 바람에 너무 오래 걸려요. 그냥 지금부터 들어오는 새 뉴스만 처리하고 싶어요."
운영자의 설정: auto.offset.reset 조정
- auto.offset.reset (기본값: latest): "정확히 이전에 처리한 오프셋이 기억나지 않는다면, 그냥 지금부터 들어오는 새로운 기사부터 처리하세요."
- auto.offset.reset = latest (기본값이므로 명시하지 않아도 되지만, 의도를 명확히 할 때 유용)
설명: latest로 설정하면 컨슈머는 이전에 커밋된 유효한 오프셋이 없거나, 오프셋이 너무 오래되어 만료된 경우, 현재 브로커에 있는 가장 최신(latest) 레코드부터 소비를 시작합니다. 이는 과거 데이터를 다시 처리할 필요가 없는 시나리오에 적합합니다. 만약 "모든 과거 기사부터 다시 분석해야 한다"면 earliest로 설정해야 합니다.
4.6 오프셋과 커밋
Kafka는 다른 메시지 큐와 달리 컨슈머가 메시지를 읽었다는 확인(Acknowledgement)을 브로커가 직접 추적하지 않다. 대신, 컨슈머 자신이 각 파티션에서 어디까지 읽었는지 그 위치(오프셋)를 Kafka 내부에 기록한다. 이 위치를 업데이트하는 것이 오프셋 커밋(Offset Commit)이다.
컨슈머는 자신이 성공적으로 처리한 마지막 메시지의 다음 오프셋을 커밋한다. 이전의 모든 메시지들은 성공적으로 처리되었다고 암묵적으로 가정하는 방식으로, 이렇게 커밋된 오프셋은 내부 토픽인 __consumer_offsets에 저장된다.
- 재시작 및 리밸런싱: 컨슈머가 갑자기 중단되거나, 컨슈머 그룹에 새로운 컨슈머가 추가되어 파티션 재할당(리밸런싱)이 발생할 때, 새로 할당된 컨슈머는 마지막으로 커밋된 오프셋부터 작업을 다시 시작한다.
- 데이터 중복 및 유실 위험
- 만약 커밋된 오프셋보다 실제로 처리된 마지막 오프셋이 더 크다면, 커밋되지 않은 메시지들은 컨슈머가 재시작/리밸런싱될 때 다시 처리(중복)될 수 있다.
- 반대로 커밋된 오프셋보다 실제로 처리된 마지막 오프셋이 더 작다면, 처리되지 않은 메시지들이 누락(유실)될 수 있다.
4.6.1 자동 커밋 (enable.auto.commit = true)
가장 간단한 방법은 컨슈머에게 오프셋 커밋을 맡기는 방법이다.
- 동작:
poll()호출 시 주기적으로 마지막 오프셋을 자동으로 커밋 - 위험성: 데이터 중복 또는 유실을 야기할 수 있다. 데이터를 처리한 직후와 자동 커밋이 실행되기 전 사이에 장애가 발생하면, 재시작 후 마지막 커밋 위치부터 다시 처리하여 데이터가 중복될 수 있다.
- 정확히 한 번 처리(Exactly Once Processing)을 보장하기 어렵다.
4.6.2 현재 오프셋 커밋하기 & 4.6.3 비동기적 커밋 (enable.auto.commit = false)
대부분의 개발자는 유실을 피하고, 중복 메시지를 줄이기 위해 대부분 오프셋 커밋 시점을 직접 제어하길 원한다. enable.auto.commit = false로 지정한 뒤, 명시적으로 커밋을 호출할 때만 사용할 수 있다.
consumer.commitSync(): 동기적 커밋. 커밋이 성공할 때까지 블로킹(blocking)된다. 성공이 보장되지만 처리량이 감소할 수 있습니다. 확실한 처리가 필요할 때 사용한다.
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
// 모든 레코드 처리 로직
System.out.printf("topic = %s, partition = %d, offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
try {
consumer.commitSync(); // 모든 레코드에 대한 처리가 완료되면, 추가 메시지를 폴링하기 전에 commitSync를 호출해서 해당 배치의 마지막 오프셋을 커밋함
} catch (CommitFailedException e) {
log.error("commit failed", e); // 해결할 수 없는 에러가 발생하기 않는 한, commitSync는 커밋을 재시도
}
}
consumer.commitAsync(): 비동기적 커밋. 커밋 요청만 보내고 바로 다음 작업을 수행한다. 동기적 커밋의 블로킹으로 인한 처리량 제한을 해결하기 위해 비동기적 커밋을 사용할 수 있다.
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
// 모든 레코드 처리 로직
System.out.printf("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
consumer.commitAsync(); // 비동기적으로 커밋하고 다음 poll() 준비
}
- 단점은 재시도를 하지 않기 때문에 커밋 요청을 보낸 뒤, 처리를 계속하다가 실패할 경우 실패가 났다는 사실과 함께 오프셋이 로그되도록 순서를 조정할 수 있다.
4.6.4 동기적 커밋과 비동기적 커밋을 함께 사용하기
일반적인 상황에서는 commitAsync()를 사용하여 처리량을 높이고, 간헐적인 커밋 실패는 다음 커밋이 성공적으로 처리되면 문제가 되지 않도록 할 수 있다. 하지만 애플리케이션이 종료되거나 리밸런싱이 발생하기 직전과 같이 "마지막 커밋"이 중요할 때는 commitAsync()와 commitSync()를 조합하는 전략을 사용할 수 있다.
Duration timeout = Duration.ofMillis(100);
try {
while (!closing) { // 애플리케이션이 닫히지 않았다면
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
// 레코드 처리
}
consumer.commitAsync(); // 평소에는 빠르고 비동기적인 커밋 사용
}
} catch (Exception e) {
log.error("Unexpected error", e);
} finally {
try {
consumer.commitSync(); // 애플리케이션 종료 직전에는 동기적으로 확실하게 커밋
// 컨슈머를 닫는 상황에는 다음 커밋이 없으므로 commitSync()를 호출한다. 커밋이 성공하거나 회복 불가능한 에러가 발생할 때까지 시도함
} finally {
consumer.close(); // 컨슈머 종료
}
}
finally 블록은 while 루프가 정상적으로 끝나거나, 예상치 못한 오류(Exception)가 발생했을 때 반드시 실행되는 부분. 애플리케이션을 안전하게 마무리하는 역할을 한다.
4.6.5 특정 오프셋 커밋하기
배치 중간에 특정 오프셋을 커밋하고 싶을 때가 있다. 예를 들어, poll()이 매우 큰 배치를 반환했는데, 그 배치 중간에 컨슈머가 죽으면 나머지 메시지들을 다시 처리해야 하는 부담(리밸런싱)을 줄이고 싶을 때 유용하다.
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
int count = 0;
// ... (초기화 코드)
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
// 각 레코드 처리
System.out.printf("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
// 현재 처리 중인 레코드의 다음 오프셋을 맵에 저장
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, "no metadata")
);
// 예를 들어 1000개 레코드마다 비동기적으로 현재 오프셋 커밋
if (count % 1000 == 0) {
consumer.commitAsync(currentOffsets, null); // 콜백 없이 커밋
}
count++;
}
}4.7 리밸런스 리스너
리밸런싱이 발생할 때, ConsumerRebalanceListener를 사용하면 파티션 소유권이 변경되기 직전/직후에 원하는 동작을 실행할 수 있다. (정리 작업을 위해)
- onPartitionsAssigned(Collection<TopicPartition> partitions)
- 파티션 할당 후, 소비 시작 전에 호출되어 상태 로드 및 오프셋 탐색과 같은 준비 작업을 한다.
- onPartitionsRevoked(Collection<TopicPartition> partitions)
- 파티션 회수 시 호출되어 마지막 오프셋을 커밋하여 데이터 중복을 방지한다. 컨슈머가 파티션을 해제하기 전에 마지막으로 처리한 메시지의 오프셋을 커밋하여, 다음으로 해당 파티션을 가져갈 컨슈머가 어디서부터 작업을 시작해야 할지 알 수 있도록 한다.
- onPartitionsLost(Collection<TopicPartition> partitions)
- 협력적 리밸런싱 중 예외적인 상황에서 호출되며, 파티션 관련 자원을 정리한다. 해당 파티션과 함께 사용되던 모든 상태나 리소스를 정리한다.
비유적 설명
리밸런스 리스너는 여러 컨슈머가 팀을 이루어 일할 때, 업무 인수인계 규칙을 정해주는 관리자라고 생각하면 됩니다.
팀원이 갑자기 그만두거나(컨슈머 장애) 새로 들어올 때(컨슈머 추가) 업무를 재분배(리밸런스)해야 하는데, 이때 그냥 아무렇게나 하면 일이 엉망이 되겠죠? 그래서 이 '관리자'가 꼭 필요한 겁니다.
관리자(리스너)가 언제 필요할까요?
가장 중요한 상황은 "내가 하던 일을 다른 팀원에게 넘겨주기 직전"
1. 파티션을 뺏기기 직전: onPartitionsRevoked()
- 상황: 팀원 A가 1번 책상(파티션)에서 서류 100장 중 50장까지 처리했는데, 갑자기 다른 업무를 맡게 되어 1번 책상을 팀원 B에게 넘겨줘야 합니다.
- 리스너가 없다면?: 팀원 B는 A가 어디까지 했는지 모릅니다. 그래서 처음부터 다시 하거나(데이터 중복 처리), 60번부터 시작해서 중간 서류를 빠뜨릴(데이터 유실) 수 있습니다.
- 리스너가 있다면(onPartitionsRevoked): 관리자가 "A씨, 책상 넘기기 전에 '50번까지 완료함' 이라고 포스트잇에 써서 붙여놓고 가세요!"라고 지시합니다.
- 이것이 바로 onPartitionsRevoked의 가장 중요한 역할, 즉 마지막으로 처리한 위치(오프셋)를 커밋하는 것입니다. 이 덕분에 다음 컨슈머가 작업을 정확히 이어서 할 수 있습니다.
2. 새 파티션을 할당받은 직후: onPartitionsAssigned()
- 상황: 팀원 B가 1번 책상을 새로 할당받았습니다.
- 리스너가 없다면?: B는 그냥 자기 마음대로 일을 시작할 수 있습니다.
- 리스너가 있다면(onPartitionsAssigned): 관리자가 "B씨, 1번 책상에 붙어있는 포스트잇 확인하고, 거기서부터 이어서 작업하세요. 그리고 1번 책상 전용 계산기도 챙기세요."라고 지시합니다.
- 즉, 새로 할당받은 파티션에서 어디부터 작업을 시작해야 할지 확인하거나, 해당 파티션 처리에 필요한 초기 데이터(상태)를 로딩하는 등의 준비 작업을 할 수 있습니다.
3. (특수한 경우) 파티션을 갑자기 잃었을 때: onPartitionsLost()
- 상황: 협력적 리밸런싱이라는 고급 기술을 쓸 때, 정상적인 인수인계 절차 없이 파티션을 갑자기 뺏기는 경우가 아주 드물게 있습니다.
- 리스너가 있다면(onPartitionsLost): 관리자가 "A씨, 1번 책상이 갑자기 사라졌네요. 그냥 관련 서류들만 잘 정리하고 마무리하세요."라고 지시합니다.
- 주로 해당 파티션을 처리하며 사용했던 자원(메모리, 캐시 등)을 정리하는 역할을 합니다.
4.8 특정 오프셋의 레코드 읽어오기
다른 오프셋으로부터 읽기를 시작하고 싶은 경우, seek() 메소드를 사용하면 원하는 위치로 강제 이동시킬 수 있다.
seekToBeginning(): 파티션의 가장 처음으로 이동seekToEnd(): 파티션의 가장 마지막으로 이동seek(partition, offset): 지정된 파티션의 특정 오프셋으로 정확하게 이동
4.9 폴링 루프를 벗어나는 방법
애플리케이션을 안전하게 종료하려면 while(true) 루프를 빠져나와야 한다. poll() 루프를 안전하게 종료하는 방법은 다음과 같다.
- consumer.wakeup() 호출: 컨슈머 루프를 종료하기 위해 다른 스레드에서 consumer.wakeup()을 호출한다. 이 메서드는 다른 스레드에서 호출해도 안전한 유일한 컨슈머 메서드이다.
- WakeupException 처리: wakeup() 호출 시 poll()은 WakeupException을 발생시키며 즉시 종료되거나, 다음 poll() 호출 시 예외가 던져질 것이다. 이 예외는 별도로 처리할 필요는 없다.
- consumer.close() 호출: WakeupException으로 poll() 루프를 벗어난 후, 반드시 consumer.close()를 호출한다.
- close()는 필요한 경우 오프셋을 커밋하여 데이터 손실을 방지한다.
- close()는 컨슈머가 그룹을 떠남을 그룹 코디네이터에게 알린다.
- 이 알림으로 인해 그룹 코디네이터는 즉시 리밸런싱을 트리거하여 종료된 컨슈머의 파티션이 빠르게 다른 컨슈머에게 할당되도록 하여 서비스 연속성을 보장한다.
4.10 디시리얼라이저
Kafka에 이벤트를 생성할 때 사용한 시리얼라이저는 해당 이벤트를 소비할 때 사용할 디시리얼라이저와 반드시 일치해야 한다. 예를 들어, IntSerializer로 직렬화된 데이터를 StringDeserializer로 역직렬화하려고 하면 좋은 결과를 기대할 수 없다. 이는 개발자로서 각 토픽에 어떤 시리얼라이저가 사용되었는지 추적하고, 해당 토픽이 사용하는 디시리얼라이저가 해석할 수 있는 데이터만 포함하고 있는지 확인해야 함을 의미한다.
최근 Kafka는 Serde (Serializer/Deserializer의 줄임말) 인터페이스를 통해 시리얼라이저와 디시리얼라이저 쌍을 편리하게 관리하는 방식이 널리 사용된다. 특히 Kafka Streams 애플리케이션에서는 Serde가 필수적으로 사용되며, 일반 KafkaConsumer에서도 유연한 타입 관리를 위해 활용될 수 있다. Serde는 기본적으로 Serializer와 Deserializer 인터페이스를 모두 구현하고 있어, 하나의 객체로 직렬화와 역직렬화를 모두 처리할 수 있도록 한다. Kafka 클라이언트 라이브러리는 Serdes 클래스를 통해 다양한 기본 Serde 구현체들을 제공한다.
4.10.1 커스텀 디시리얼라이저
사용자 정의 객체를 역직렬화하기 위해 org.apache.kafka.common.serialization.Deserializer 인터페이스를 구현하여 커스텀 디시리얼라이저를 만들 수 있다. 이 인터페이스는 configure(), deserialize(), close() 세 가지 메서드를 포함한다.
deserialize() 메서드 내에서는 입력으로 받은 바이트 배열(byte[] data)을 파싱하여 원래의 객체로 재구성하는 로직을 구현하게 된다. 예를 들어, 프로듀서가 객체의 특정 필드를 정해진 순서와 크기로 바이트 배열에 저장했다면, 디시리얼라이저는 그 순서와 크기에 맞춰 바이트를 읽어내어 객체의 필드를 채울 것이다. 오류 발생 시에는 SerializationException을 던지도록 한다.
하지만 커스텀 시리얼라이저/디시리얼라이저를 직접 구현하는 것은 일반적으로 권장되지 않는다. 이는 프로듀서와 컨슈머 간에 매우 강한 결합을 발생시키고, 변경에 취약하며 오류가 발생하기 쉽기 때문이다. 예를 들어, 객체 필드의 순서나 타입이 변경되면 관련 시리얼라이저와 디시리얼라이저 코드를 모두 업데이트해야 한다.
따라서, 직접 구현하기보다는 JSON, Thrift, Protobuf, 또는 Avro와 같은 표준 메시지 형식을 사용하는 것이 훨씬 바람직하다.
4.10.2 Avro 디시리얼라이저 사용하기
Avro는 스키마 기반의 데이터 포맷이며, 스키마 레지스트리(Schema Registry)와 함께 사용하여 데이터 호환성을 자동으로 관리하는 데 유용하다.
Duration timeout = Duration.ofMillis(100);
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092"); // Kafka 브로커 주소 설정
props.put("group.id", "CountryCounter"); // 컨슈머 그룹 ID 설정
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer"); // 메시지 키는 String으로 역직렬화
// Avro 메시지를 역직렬화하기 위해 KafkaAvroDesrializer를 사용
props.put("value.deserializer",
"io.confluent.kafka.serializers.KafkaAvroDeserializer"); // 메시지 값은 Avro 디시리얼라이저 사용
props.put("specific.avro.reader","true"); // Avro 스키마를 사용하여 특정 자바 클래스로 역직렬화하도록 설정
props.put("schema.registry.url", schemaUrl); // 스키마 레지스트리 서버의 URL 설정. Avro 디시리얼라이저가 스키마를 찾아올 때 사용
// schema.registry.url은 새로운 매개변수로 스키마가 저장된 곳을 가리킴. 이렇게 설정하면 프로듀서가 등록한 스키마를 컨슈머가 메시지를 역직렬화하기 위해서 사용할 수 있음
String topic = "customerContacts"; // 소비할 토픽 이름
KafkaConsumer<String, Customer> consumer = new KafkaConsumer<>(props); // KafkaConsumer 인스턴스 생성
consumer.subscribe(Collections.singletonList(topic)); // 지정된 토픽 구독
System.out.println("Reading topic:" + topic);
while (true) {
ConsumerRecords<String, Customer> records = consumer.poll(timeout); // Kafka에서 레코드 폴링
// 생성된 Customer 클래스를 레코드 밸류 타입으로 지정함
for (ConsumerRecord<String, Customer> record: records) {
System.out.println("Current customer name is: " +
record.value().getName()); // 역직렬화된 Customer 객체에서 이름 필드 접근
// record.value는 Customer 인스턴스이므로 이 객체의 멤서드 역시 호출할 수 있음
}
consumer.commitSync(); // 처리된 오프셋 동기적으로 커밋
}4.11 독립 실행 컨슈머: 컨슈머 그룹 없이 컨슈머를 사용해야 하는 이유와 방법
일반적으로 Kafka 컨슈머는 컨슈머 그룹에 속하여 파티션을 자동으로 할당받고 리밸런싱을 통해 부하를 분산한다. 하지만 때로는 이런 복잡한 메커니즘 없이 단일 컨슈머가 특정 토픽의 모든 파티션 또는 특정 파티션만을 읽어야 할 때가 있다. 이때, 컨슈머는 토픽을 subscribe()하는 대신, 특정 파티션(들)을 직접 assign()한다. 컨슈머는 subscribe와 assign을 동시에 사용할 수 없다.
주의사항은 다음과 같다.
- 독립 실행 컨슈머는 리밸런싱이 발생하지 않는다.
- 토픽에 새로운 파티션이 추가되더라도 자동으로 인지하지 못한다. 주기적으로 consumer.partitionsFor()를 확인하거나, 파티션 추가 시 애플리케이션을 재시작하여 수동으로 대응해야 한다.
4.12 요약
- 컨슈머 그룹과 이벤트 소비: Kafka 컨슈머 그룹의 작동 방식과 여러 컨슈머가 토픽의 이벤트를 공유하여 읽는 방법을 심층적으로 다루었다. 컨슈머가 토픽을 구독하고 지속적으로 이벤트를 읽는 실제 예시도 제시했다.
- 주요 컨슈머 설정: 컨슈머 동작에 영향을 미치는 가장 중요한 설정 매개변수들을 살펴보았다.
- 오프셋과 커밋: 컨슈머가 오프셋을 어떻게 추적하는지에 대해 많은 부분을 할애하여 설명했다. 신뢰할 수 있는 컨슈머를 작성하는 데 필수적인 오프셋 커밋의 다양한 방법들을 자세히 설명했다.
- 컨슈머 API의 추가 기능: 리밸런스 처리 및 컨슈머를 깔끔하게 종료하는 방법과 같은 컨슈머 API의 추가적인 부분들을 논의했다.
- 디시리얼라이저: 컨슈머가 Kafka에 저장된 바이트를 애플리케이션이 처리할 수 있는 자바 객체로 변환하는 데 사용하는 디시리얼라이저에 대해 다루었다. 특히 Kafka에서 가장 흔히 사용되는 Avro 디시리얼라이저에 대해 상세히 설명했다.
참고
- 카프카 핵심 가이드 2판
- https://youtu.be/xqrIDHbGjOY?si=DplA2_2NjZX2e2aj
'스터디&세미나' 카테고리의 다른 글
| [스터디] Kafka와 Redis를 활용한 대규모 실시간 시청자 수(CCU) 집계 시스템 설계 (0) | 2026.01.07 |
|---|---|
| [AWS] Strands Agent 실습 (AWS Community Day 2025) (0) | 2025.11.10 |
| [Kafka] 카프카 핵심 가이드 - 3 (카프카 프로듀서) (1) | 2025.07.07 |
| [Kafka] 카프카 핵심 가이드 - 2 (Windows WSL 카프카 설치) (1) | 2025.07.01 |
| [Kafka] 카프카 핵심 가이드 - 1 (1) | 2025.07.01 |
- Total
- Today
- Yesterday
- SPARQL
- Postgis
- pdfmathtranslate
- rdffox
- Kafka
- PEFT
- vscode
- AWS
- ChatGPT
- python
- Encoding
- 지식그래프
- PostgreSQL
- Vue3
- Claude
- LLM
- polars
- docker
- rdflib
- pandas
- cursorai
- vertorsearch
- TextRank
- deepseek
- vervel
- hadoop
- MongoDB
- 키워드추출
- vectorsearch
- geospy
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |