

티스토리 뷰
https://github.com/lovit/KR-WordRank
GitHub - lovit/KR-WordRank: 비지도학습 방법으로 한국어 텍스트에서 단어/키워드를 자동으로 추출하는
비지도학습 방법으로 한국어 텍스트에서 단어/키워드를 자동으로 추출하는 라이브러리입니다. Contribute to lovit/KR-WordRank development by creating an account on GitHub.
github.com
https://pypi.org/project/krwordrank/
krwordrank
KR-WordRank: Korean Unsupervised Word/Keyword Extractor
pypi.org
설치
pip install krwordrank기본 활용
from krwordrank.word import summarize_with_keywords
keywords = summarize_with_keywords(sentence_list)
keywords
>>{'대피소': 1.6973963414238353,
'이용': 1.2365894082366355,
'지진': 1.1830066785290532,
'데이': 0.9906795680773113,
'위치': 0.8133123061030108,
'서울': 0.793937004234468,
'현황': 0.7869782218250642}성능이 나쁘진 않은데, 짧은 문장이라 키워드가 적게 나옴.
문장 전처리를 위한 함수
참고 블로그
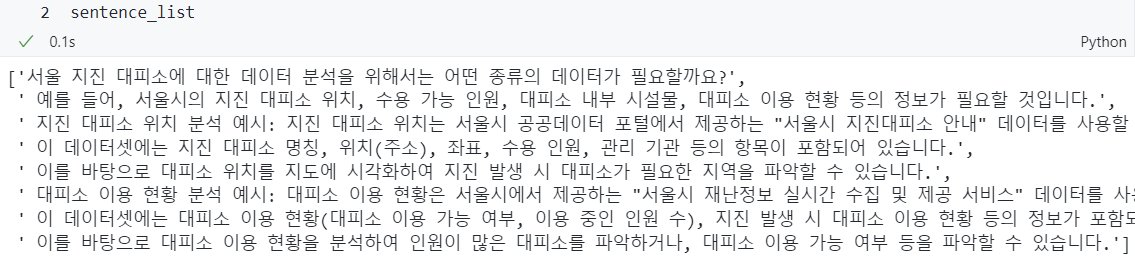
ver 1 문장만 고려하여 나누기
text = "서울 지진 피해에 대한 데이터 분석을 위해서는 어떤 종류의 데이터를 사용해야 할지 먼저 생각해보아야 합니다. 예를 들어, 지진 발생 시간, 지진 규모, 지진 발생 지역, 피해 규모 등의 정보가 필요할 것입니다. 서울 지진 피해 분석 예시: 서울 지역에서 최근 몇 년간 발생한 지진 데이터를 수집하여 지진 발생 건수, 지진 규모, 지진 발생 지역 등의 정보를 파악할 수 있습니다. 이를 바탕으로 서울 지역에서 지진 발생이 가장 많은 지역, 지진 규모와 피해 규모 간의 상관 관계, 지진 발생 시간대 등을 분석할 수 있습니다. 또한, 특정 지역에서의 지진 발생 시 피해 규모가 어떻게 나타나는지 분석하여 지진 대비 대응 전략을 마련할 수 있습니다. 서울 지진에 대한 데이터는 국가지진정보센터에서 제공하는 '국내 지진 정보 시스템'에서 확인할 수 있습니다. 이 시스템에서는 지난 1년간의 국내 지진 정보를 확인할 수 있으며, 서울 지역에서 발생한 지진 정보도 포함되어 있습니다. 이를 바탕으로 데이터를 수집하고 분석할 수 있습니다."
import re
def split_sentences(text):
sentences = text.replace(". ",".")
sentences = re.sub(r'([^\n\s\.\?!]+[^\n\.\?!]*[\.\?!])', r'\1\n', text).strip().split("\n")
return sentences.?!을 기준으로 문장을 구분하고('\1\n') split('\n')하여 쪼개서 리스트로 만들기
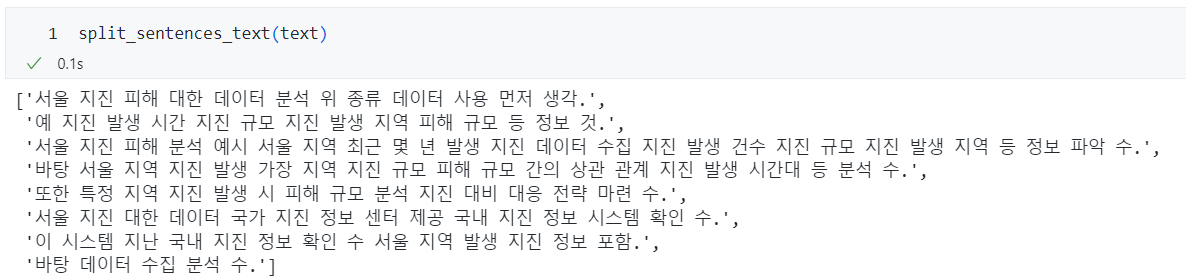
ver2 명사로만 문장을 구성하여 나누기
konlpy 설치하기!
// java 1.7이상인지 확인
pip install JPype1>=0.7.0
pip install konlpyOkt로 명사를 구분하고, 명사로만 문장을 구성하도록 함
from konlpy.tag import Okt
import re
def split_noun_sentences(text):
okt = Okt()
sentences = text.replace(". ",".")
sentences = re.sub(r'([^\n\s\.\?!]+[^\n\.\?!]*[\.\?!])', r'\1\n', sentences).strip().split("\n")
result = []
for sentence in sentences:
if len(sentence) == 0:
continue
sentence_pos = okt.pos(sentence, stem=True)
nouns = [word for word, pos in sentence_pos if pos == 'Noun']
if len(nouns) == 1:
continue
result.append(' '.join(nouns) + '.')
return result
키워드 추출
명사로만 문장 구성하는게 더 결과가 깔끔함
from krwordrank.word import KRWordRank
min_count = 1 # 단어의 최소 출현 빈도수 (그래프 생성 시)
max_length = 10 # 단어의 최대 길이
wordrank_extractor = KRWordRank(min_count=min_count, max_length=max_length)
beta = 0.85 # PageRank의 decaying factor beta
max_iter = 20
texts = split_noun_sentences(text)
keywords, rank, graph = wordrank_extractor.extract(texts, beta, max_iter)
for word, r in sorted(keywords.items(), key=lambda x:x[1], reverse=True):
print('%8s:\t%.4f' % (word, r))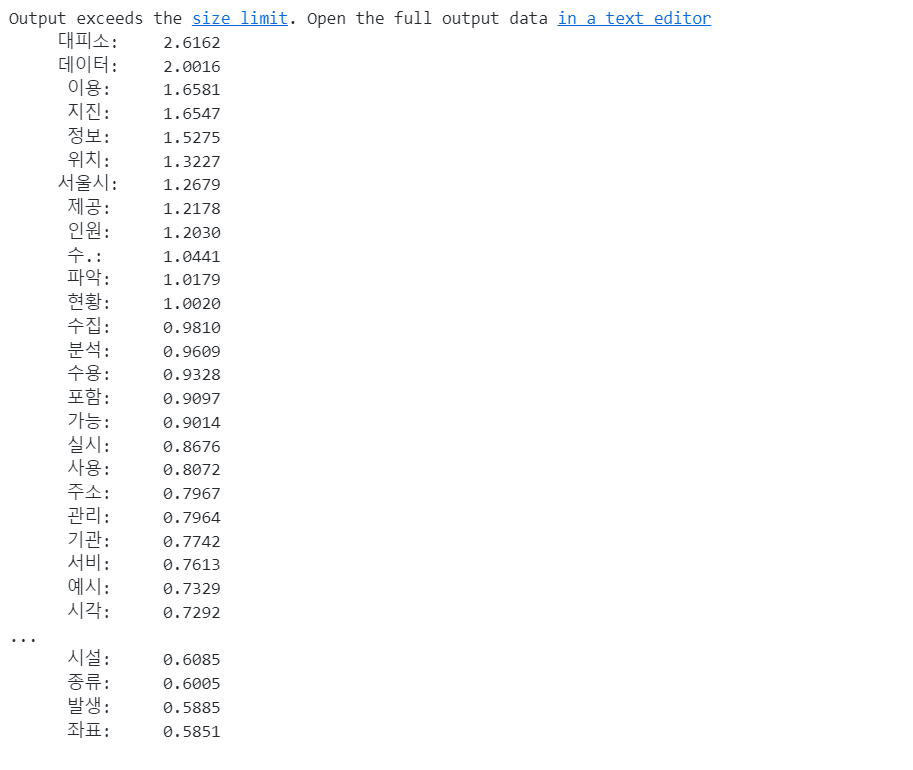
입력 텍스트가 길지않고 같은 단어를 반복하는 게 크지 않아서, min_count는 1로 설정하고, beta값은 chatGPT의 도움을 받아 이해했습니다. 0에 가까울 수록 단어마다 부여되는 값이 커지는데, 0.2/0.5/0.9로 테스트해본 결과 짧은 텍스트에서는 큰 차이가 나지 않았음
beta는 PageRank 알고리즘에서 "decaying factor"로 알려진 값으로, 현재 노드와 연결된 다른 노드들의 PageRank 값을 고려하는 정도를 조절합니다. PageRank 알고리즘은 각 노드의 중요도를 결정하기 위해 다른 노드와의 연결성을 고려합니다. 그러나 링크 구조가 복잡한 경우 링크 간의 상호작용이 너무 강력하게 작용할 수 있으므로 PageRank 값이 적절하게 분배되지 않을 수 있습니다. 이를 보완하기 위해 decaying factor beta를 도입합니다. beta는 0과 1 사이의 값으로, 일반적으로 0.85로 설정됩니다. beta가 작을수록 다른 노드의 영향력이 강해지므로 PageRank 값이 더 분산됩니다. 반면, beta가 클수록 현재 노드와 연결된 다른 노드들의 PageRank 값이 더 강하게 반영되므로 PageRank 값이 더 집중됩니다. KRWordRank에서도 beta 값이 작을수록 다른 단어들의 영향력이 강해지므로 키워드 추출 결과가 더 분산됩니다. beta 값이 클수록 해당 단어와 관련된 다른 단어들의 출현 빈도수를 보다 강하게 고려하여 키워드 추출 결과가 더 집중됩니다.
문장을 쪼개지않고 키워드 추출
text를 여러문장으로 나누지 않고 text가 통으로 들어간 리스트로 만들어서 테스트
result_text = ''
sentence_pos = okt.pos(text, stem=True)
nouns = [word for word, pos in sentence_pos if pos == 'Noun']
result_text = ' '.join(nouns)
noun_single_text_list = []
noun_single_text_list.append(result_text)from krwordrank.word import KRWordRank
min_count = 1 # 단어의 최소 출현 빈도수 (그래프 생성 시)
max_length = 10 # 단어의 최대 길이
wordrank_extractor = KRWordRank(min_count=min_count, max_length=max_length)
beta = 0.85 # PageRank의 decaying factor beta
max_iter = 20
texts = noun_single_text_list
keywords, rank, graph = wordrank_extractor.extract(texts, beta, max_iter)
for word, r in sorted(keywords.items(), key=lambda x:x[1], reverse=True):
print('%8s:\t%.4f' % (word, r))
별 차이가 없음. 차이가 크지 않으면 오히려 코드 효율화를 위해 굳이 문장을 쪼개지 않아도 될것같음
Github 코드 공유
https://github.com/shinysong/korean-keyword-extract/tree/main
GitHub - shinysong/korean-keyword-extract: textrankr, krwordrank, keybert 라이브러리
textrankr, krwordrank, keybert 라이브러리. Contribute to shinysong/korean-keyword-extract development by creating an account on GitHub.
github.com
'개발일지' 카테고리의 다른 글
| [Elasticsearch] 검색 쿼리 단어 중 특정 단어에 가중치 - multi_match, match, should (1) | 2023.05.01 |
|---|---|
| [NLP] Kiwi 설치와 keyBert 한글 키워드 추출 (1) | 2023.04.28 |
| [TextRank] textrankr과 konlpy를 사용한 한국어 요약 (1) | 2023.04.27 |
| [TextRank] pytextrank와 spacy 한글 키워드 추출 (0) | 2023.04.27 |
| [django+elasticsearch+vue.js] (1) - 엘라스틱서치와 장고 설치하기 (0) | 2022.10.24 |
- Total
- Today
- Yesterday
- Vue3
- Claude
- PostgreSQL
- vscode
- PEFT
- Kafka
- ChatGPT
- rdffox
- hadoop
- vectorsearch
- Encoding
- MongoDB
- python
- vertorsearch
- graphrag
- docker
- rdflib
- AWS
- polars
- SPARQL
- LLM
- knowledgegraph
- TextRank
- pandas
- pdfmathtranslate
- 지식그래프
- knowlegegraph
- Postgis
- geospy
- 키워드추출
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |