
티스토리 뷰
http://arxiv.org/abs/2106.09685
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
소개 (Introduction)
"LoRA"는 마이크로소프트에서 출시된 언어 모델로, 사전 학습된 파라미터를 고정시키고 새로운 파라미터를 도입하여 효율적인 차원 축소 및 복구를 통해 모델의 학습을 진행하는 방법을 제안합니다. 이는 기존의 큰 언어 모델의 파라미터를 모두 다시 학습시키는 것보다 효율적이며, 특히 다양한 서브 태스크에 대한 적용이 가능합니다.
We take inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension. We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”, leading to our proposed Low-Rank Adaptation (LoRA) approach.
학습 방법 (Our Method)
로라는 전체 파라미터를 사용하지 않고도 필요한 정보를 충분히 반영할 수 있는 접근법을 제시합니다. 이를 위해 무작위 가우시안 행렬인 A와 0으로 초기화된 행렬인 B를 도입하여, 이들을 사용하여 차원 축소와 복구를 수행합니다. 또한, 초기 학습된 파라미터인 W0는 고정시키고, 새로운 파라미터인 세타를 학습하는데, 이는 적은 디멘션을 가지고 있어 학습이 효율적으로 이루어집니다.
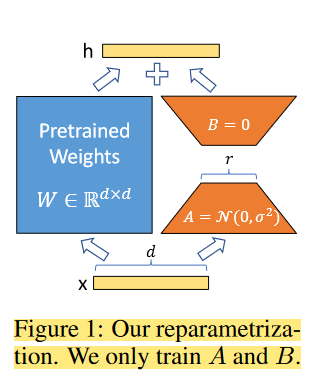
로라가 제안된 배경 중 하나는 기존의 언어 모델의 사전 학습 및 적응 과정에서 발생하는 문제입니다. 특히, 시퀀스 길이를 예약하는 방식은 정보 손실과 성능 저하의 원인이 될 수 있습니다. 로라는 이러한 문제를 극복하고자 설계되었으며, 다양한 서브 태스크에 대한 대처가 가능하다는 특징을 가지고 있습니다.
기존 해결책과의 비교 (Aren't Existing Solutions Good Enough?)
로라의 등장 배경 중 하나는 기존의 어댑터 레이나 입력 레이어의 최적화 시도가 있었음에도 불구하고, 추론 지연이 발생하고 있었다는 점입니다. 로라는 이러한 한계를 극복하며 선행 연구에 비해 20-30%의 속도 향상을 보여줍니다. 또한, 시퀀스 길이를 예약하는 방식이 가지는 문제점들을 지적하고 있습니다.
- 시퀀스 길이가 줄어들면 생기는 문제점은?
- 정보 손실: 시퀀스 길이가 줄어들면 입력으로부터의 정보량이 감소하게 됩니다. 모델이 이전의 정보를 고려하는 데 제한이 생겨, 더 긴 문맥을 이해하는 데 어려움이 발생할 수 있습니다.
- 문맥 파악의 어려움: 특히 언어 모델의 경우, 긴 문장이나 긴 문맥에서의 의미 파악이 중요할 수 있습니다. 시퀀스 길이의 감소로 인해 이러한 긴 문맥을 파악하는 능력이 제한되어 어려움이 발생할 수 있습니다.
- Downstream 작업 성능 저하: 원래의 모델이나 작업에 따라 필요한 긴 시퀀스 길이가 있다면, 이를 줄이면 해당 작업의 성능이 저하될 수 있습니다. 특히 언어 모델의 경우, 번역, 요약, 질문 응답과 같은 작업에서는 높은 문맥을 고려해야 할 때가 많습니다.
- Prompt 조정의 어려움: 다운스트림 작업에 대한 최적의 성능을 내기 위해 모델을 조정하거나 prompt를 튜닝하는 경우, 긴 시퀀스 길이가 필요할 수 있습니다. 이를 위해 일부를 예약하게 되면, prompt 튜닝에 사용 가능한 시퀀스 길이가 줄어들어 조정이 어려워질 수 있습니다.
결론 (Conclusion)
로라는 간단하면서도 효과적인 방법으로 큰 언어 모델의 적응성을 향상시키는 방법을 제안하고 있습니다. 초기 학습된 파라미터를 고정시키고 필요한 정보를 적은 디멘션으로 효율적으로 표현함으로써, 언어 모델의 성능을 향상시킬 수 있음을 보여주고 있습니다. 추후에는 더 다양한 서브 태스크에 적용할 수 있는 가능성을 탐구할 것으로 기대됩니다.
'논문' 카테고리의 다른 글
| 생성 AI와 소프트웨어 개발과 법제도적 동향 (2) | 2025.01.02 |
|---|---|
| [Knowledge Graph] Unifying Large Language Models and Knowledge Graphs: A Roadmap (0) | 2024.05.20 |
| [논문리뷰] GPT-1 Improving Language Understanding by Generative Pre-Training (2) | 2024.02.01 |
| [논문리뷰] P-tuning-GPT Understands, Too(Version2) (1) | 2024.01.24 |
| [논문리뷰] Prefix-Tuning: Optimizing Continuous Prompts for Generation (1) | 2024.01.22 |
- Total
- Today
- Yesterday
- geospy
- ChatGPT
- rdflib
- pandas
- vectorsearch
- rdffox
- Encoding
- cursorai
- TextRank
- 키워드추출
- writerow
- hadoop
- psycopg
- polars
- Postgis
- 지식그래프
- MongoDB
- python'
- vertorsearch
- python
- vscode
- pdfmathtranslate
- Claude
- PostgreSQL
- deepseek
- PEFT
- LLM
- vervel
- Vue3
- SPARQL
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |